
Jeder spricht von künstlicher Intelligenz. Was KI tatsächlich bedeutet, wissen jedoch die wenigsten, so scheint es. Wirtschaft, Politik und Gesellschaft neigen deshalb zum Buzzword-Bingo. Warum der Hype um KI alles andere als hilfreich ist, möchte ich in diesem Artikel erläutern. Wir brauchen begriffliche Klarheit und eine Diskussion darüber, warum wir besser von Machine Learning anstatt von KI sprechen sollten.
Es braucht eine allgemein gültige KI-Definition
Im öffentlichen Diskurs um Künstliche Intelligenz gibt es derzeit keine klare Definition dafür, was KI überhaupt ist. Und das ist ein Problem. Denn technologischer Fortschritt braucht einen gemeinsamen Nenner. Andernfalls riskieren wir weiter hinterher zu hinken – wir schüren Verwirrung oder gar Ängste um KI-Vorstellungen aus Sci-Fi-Thrillern.
Als Co-Founder und CEO von Adtriba, einem Startup, das mit Machine Learning Marketing-Managern zu besseren Entscheidungen verhilft, beschäftige ich mich tagtäglich mit künstlicher Intelligenz. Dennoch irritiert mich der Hype um KI, da er uns nicht weiterbringt und irreführend ist.
Es ist wenig hilfreich, wenn vermeintliche Experten den Diskurs um künstliche Intelligenz anheizen und in eine falsche Richtung lenken, statt KI endlich zu entmystizifierem. KI wurde als Begriff bereits in den 1950er Jahren von dem US-amerikanischen Informatiker John McCarthy geprägt. KI ist ein Teilgebiet der Informatik, das darauf abzielt, bestimmte Fähigkeiten menschlichen Denkens auf Computersysteme zu übertragen und damit Maschinen zu konstruieren, die selbstständig Probleme erkennen und lösen können. Auch wenn sich die Technologie seither enorm weiterentwickelt hat, kann festgehalten werden, dass bereits zu diesem Zeitpunkt von künstlicher Intelligenz die Rede war.
Egal wie ausgereift die KI-Technologie also sein mag: In der Realität fällt unter den Begriff KI alles, was beim Versuch die menschliche Intelligenz nachzubilden, entsteht. Und dies geschieht bereits, wenn ein Computersystem auf simplen Regeln basiert:
“Technically if I use a rules-based system, I can say that my system is intelligent, and people who know about AI may frown upon it, but they cannot technically say that I’m lying. Technically, even a simple calculator could be considered AI.”
Dr. Julio Amador Diaz Lopez, Professor am Imperial College London
Machine Learning treibt die Fortschritte heutiger KI-Systeme an
Heutzutage wird die Verbreitung von KI-Systemen durch Fortschritte im Bereich des maschinellen Lernens vorangetrieben. Dieser Umstand hat dazu geführt, dass KI und ML häufig synonym verwendet werden. Ein Fehler, denn Machine Learning ist immer KI, aber KI ist nicht immer Machine Learning
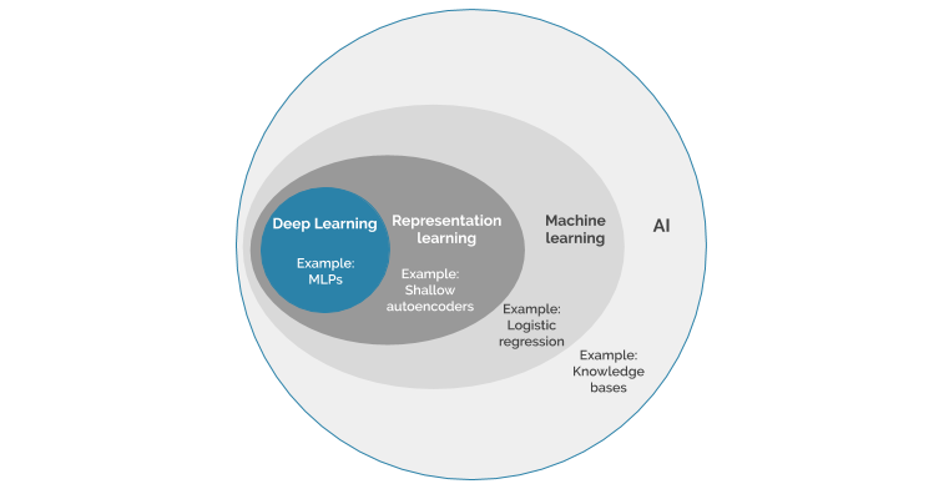
Wenn wir heute von KI sprechen, meinen wir also im Grunde Machine Learning bzw. Deep Learning, was wiederum ein Teilgebiet von ML ist. Machine Learning wurde von Arthur Samuel als “die Fähigkeit zu lernen, ohne explizit programmiert worden zu sein” definiert. Das heißt, dass der Algorithmus – also die Regeln und Rechenanweisungen – nach denen das System oder die Software seine Entscheidungen trifft, nicht wie beim “normalen” Programmieren explizit definiert werden muss. Sondern es wird von dem System eigenständig und durch die Analyse der vorliegenden Input-Daten erlernt.
Hierzu ein Beispiel. Eine konkrete, nicht auf Machine Learning basierende Regelanweisung wäre beispielsweise: “Immer wenn Facebook oder Google an der Customer Journey beteiligt sind, werden ihnen jeweils 50 Prozent der Conversion zugerechnet.” Bei Adtriba errechnet der Machine-Learning-Algorithmus genau und ohne feste Regel, welcher Marketing-Kanal welchen Beitrag zur Conversion beisteuert, wobei er sich kontinuierlich selbst optimiert. Das System lernt, welche Bedeutung die einzelnen Touchpoints wirklich haben. Hierzu vergleicht es permanent und selbständig die riesigen Datenmengen an Journeys der Käufer mit den Journeys der Nicht-Käufer.
Deep Learning als eine Unterkategorie von Machine Learning nutzt künstliche, neuronale Netze in Kombination mit großen Datenmengen und orientiert sich an der Funktionsweise des menschlichen Gehirns. Die verwendeten neuronalen Netze sind dabei tief gestaffelt, d.h. es gibt mehrere Schichten in den Netzen und zwischen der Input- und Output-Schicht. Daher der übersetzte Name “tiefes Lernen”.
KI ist alles, was menschliche Intelligenz nachbildet
Bereits im Jahr 2001, als ich bei der privaten Krankenversicherung Deutscher Ring während meines Studiums als Werkstudent tätig war, haben wir KI-Software entwickelt. Damals noch komplett ohne Machine Learning. Es wurde ein sogenanntes wissensbasiertes System für die Bearbeitung von Versicherungsanträgen implementiert. Es ging dabei um das Wissen der Sachbearbeiter, die einen Versicherungsantrag prüfen, inklusive der Vorerkrankungen und sonstigen wichtigen Informationen. So sollte dann entschieden werden, ob und mit welchem Tarif dem Antragsteller ein Versicherungsangebot gemacht wird. Das Wissen der Sachbearbeiter wurde dabei als ein umfangreicher Satz an einfachen Regeln (If-then-else-Blöcke) in der KI implementiert. Ein Beispiel: Wenn chronische Rückenschmerzen vorlagen, erhöhte sich der Versicherungsbeitrag um X%. Ziel dieser KI-Software war, dass der Versicherungsvertreter direkt vor Ort beim potenziellen Kunden über den Antrag entscheiden konnte. Um so lange Wartezeiten bei der Antragsprüfung zu umgehen und insgesamt mehr Abschlüsse zu generieren.
Womöglich schüttelt der eine oder andere Leser nach diesem Absatz den Kopf. Ein wissensbasiertes System, basierend auf einfachen Regeln, soll bereits richtige KI sein? In der Tat. Auch wenn einige Experten dem widersprechen mögen und Behauptungen wie die folgenden aufstellen:
A) Wahre KI gibt es heute (noch) nicht. Erst dann, wenn die Maschinen von uns Menschen vollständig unabhängig ticken.
B) Neben wahrer KI gibt es auch den Einsatz von Fake-KI. Fraglich ist, inwieweit solche Aussagen zutreffen.
Insbesondere letztere Aussage stiftet nur noch mehr Verwirrung: Wenn es sich bei KI bereits um nachgebildete, also künstliche menschliche Intelligenz handelt, wie kann dann die Rede von Fake-KI sein? Dies wäre mit dem Begriff der künstlichen künstlichen Intelligenz gleichzusetzen, was wie oben geschildert wiederum nur wirklicher, also menschlicher Intelligenz entsprechen kann.
Gefakte oder “künstliche KI” kann es also nur geben, wenn Menschen die Aufgaben der vorgetäuschten KI ausführen, womit wir dann aber wieder bei wirklicher, menschlicher Intelligenz wären. Das macht semantisch auch Sinn, da künstliche KI nur wirkliche Intelligenz sein kann (das doppelte “künstliche” nivelliert sich sozusagen).
Start-ups nutzen KI-Begriff als Kosmetik
Das Problem mit dem Begriff “Fake AI” wird auch durch den Report zum Stand von KI deutlich, der im Frühjahr von der Risikokapitalfirma MMC Ventures herausgegeben wurde. Das Ergebnis: 40 Prozent aller vermeintlichen “KI-Startups” haben in der Realität diesen Titel überhaupt nicht verdient. Weil KI in Produkt, Service oder Dienstleistung nur teilweise oder überhaupt nicht stattfindet. Das bedeutet in diesem Zusammenhang auch: unter den analysierten Startups befinden sich solche, deren KI lediglich ein simples, regelbasiertes System umfasst. Sprich: sie würden Fake-KI einsetzen.
Weiterhin lautet es, dass sich ein Großteil KI insbesondere aus Marketingzwecken auf die Fahne schreibt, um ihre Attraktivität gegenüber potenziellen Investoren zu erhöhen. Wer auf KI setzt, kann schließlich mit 15-20 Prozent mehr Kapital rechnen. Hierzu ein Beispiel: In der frühen Startup-Phase wird oftmals auf KI-Systeme gesetzt. Fakt aber ist, meist verbergen sich hinter der Daten-Automatisierung Mitarbeiter. Erst nach und nach wird die menschliche durch künstliche Intelligenz ersetzt. Die Argumentation ist allerdings nicht schlüssig. Wie schon oben beschrieben, ist KI in der Realität alles, sobald es um den Versuch geht, menschliche Intelligenz nachzubilden. Und dies geschieht bereits dann, wenn ein Computersystem auf simplen Regeln basiert. Wesentlich zielführender wäre es also zu unterscheiden, ob ein Unternehmen wirklich Machine Learning einsetzt oder nicht.
Als letztes Beispiel zu der Verwirrung um den Begriff KI möchte ich folgendes Gespräch mit einer renommierten Market Research-Firma anführen. Als Startup in einem innovativen Bereich, wie Machine Learning, wird man regelmäßig von Firmen wie Forrester Research oder Gartner kontaktiert. Einerseits wollen diese Unternehmen verstehen, wie sich der Markt und die Innovationen dort entwickeln, andererseits versuchen sie ihre Dienstleistungen, wie die Platzierung im Forrester Wave Report oder Gartner Quadrant, zu verkaufen. In einem Gespräch mit einer dieser Firmen ergab sich eine aus meiner Sicht sehr lustige Situation. Nachdem ich unseren Machine-Learning-basierten Algorithmus erklärte, erklärten mir die Experten auf der Gegenseite, dass das ja nur Machine Learning sei – aber keine AI. AI sei ja schließlich selbstlernend, was dieser Machine-Learning-Algorithmus nicht sei. Erst als ich erläuterte, dass der Machine-Learning-Algorithmus und damit das Erlernte jeden Tag aktualisiert werden würde, gaben sie sich zufrieden und frohlockten “Now this is AI!”. Zu einer weiteren Zusammenarbeit kam es aber dennoch nicht.
Warum KI und Machine Learning immer nur so gut sein können, wie die Menschen hinter den Maschinen
Bei all den Möglichkeiten, die sich durch den Einsatz von Machine Learning versprochen werden, darf eines nicht vergessen werden: KI und Machine Learning sind kein Allheilmittel. Die Ergebnisse, die der ML-Algorithmus erzeugt, sind immer nur so gut, wie die Menschen, die mit unternehmensrelevanten Fragestellungen im Kopf passende Datenmengen beschafft und vorbereitet haben, sowie die Daten selbst. In vielen Fällen gibt deshalb nicht die Technik die Grenzen des ML vor, sondern die Kompetenzen der Menschen und die Qualität der zur Verfügung stehenden Daten. Damit wir als Gesellschaft bei diesem so wichtigen Thema vorankommen, sollte im ersten Schritt Klarheit über die verwendeten Begriffe herrschen. Was ist also die sinnvolle Alternative zu dem Begriff KI? Wie kann verhindert werden, dass der Begriff, der etwas umschreiben soll, das Expertenmeinungen zur Folge unser Leben so nachhaltig beeinflussen und verändern wird, wie die Nutzung von Elektrizität und Feuer, missverständlich und missbräuchlich verwendet wird?
Die Antwort ist relativ simpel: Statt von KI sollte von Machine Learning gesprochen werden. Google, als eines der führenden Machine Learning Unternehmen der Welt, nutzt den Begriff Machine Learning wesentlich häufiger als AI, ohne dass es dem Unternehmen Schaden würde. Damit schafft Google Transparenz und vermeidet gegenüber den Investoren Missverständnisse durch eine genaue und konkrete Beschreibung dessen, was für Google relevant ist. Warum also nicht von den Besten lernen?
Gegen die Verwendung des KI-Begriffs spricht auch, dass dieser meiner Erfahrung nach wesentlich häufiger von vermeintlichen Experten verwendet wird, die selbst noch nie praktische Erfahrungen in der Umsetzung von Machine Learning Algorithmen gemacht haben; bspw. in der Programmiersprache Python. Den Term KI dafür aber gerne in PowerPoint-Präsentation einsetzen. Dazu passt auch abschließend das folgende Zitat von Mat Velloso, Technical Advisor des CEO von Microsoft:
Difference between machine learning and AI:
If it is written in Python, it’s probably machine learning
If it is written in PowerPoint, it’s probably AI
Wenn ihr mehr über KI in der Praxis erfahren wollt, dann solltet ihr nicht unsere Episode mit einer der bekanntesten Köpfe der AI-Startup Szene verpassen: Dr. Anna Lukasson-Herzig, Co-Gründerin von Nyris. Ein Startup, bei dem KI mehr als nur Kosmetik ist. Release 09. März 2021 überall dort, wo es Podcast gibt.